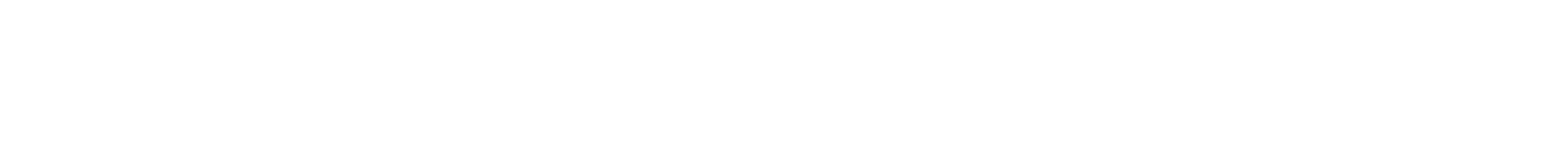

前回までの記事で、画像分類に使われるVGG16というアルゴリズムを使うことで、救急車・消防車のサイレン音を10秒ごとに識別することができるようになりました。
AIで救急車のサイレン音を解析し救急車の往来回数をカウントしよう(1)
AIで救急車のサイレン音を解析し救急車の往来回数をカウントしよう(2)
学習の段階でもGPUを搭載していない通常のPCで学習させましたが、推論の段階では、さらに踏み込んで、PCより性能の低いRaspberry Pi (ラズベリーパイ、略してラズパイ)単体で推論させてみましょう。
今回構築するシステムは以下のような構成のものです。
今回のシステムの構成図
Raspberry Pi の機種選定、ソフトウェア環境構築が必要になりますが、複雑なので、以下のページに分けて記述しました。まずは、こちらをお読みください。
Raspberry Pi に Ubuntu OS を入れてTensorflowをインストールしてみよう
必要なライブラリをインストールしよう
以下のようなコマンドを打ちます。 pipだけだとPyAudio は入りません。
python3 -m pip install -U pip
sudo apt-get install portaudio19-dev
sudo pip install pyaudio
sudo pip install librosa
sudo pip install matplotlibmatplotlib と TensorFlow のnumpy のバージョンが競合する、とメッセージが出る可能性がありますが、とりあえずはそのまま動きます。
マイクをUSBポートに挿してデバイス番号を取得しよう
USBマイクなら何でも大丈夫ですが、以下のマイクを使いました。
後段のリアルタイム音声認識を行う際には、マイクの番号(チャネルという)を確認しておく必要があります。USBマイクをRaspberry Pi に接続し、以下のコードを記述してmic_check.py などと名付け、実行してみてください。チャネル番号が表示されますので、それを後述するsave_and_predict.pyの中に記述します。

import pyaudio
pa = pyaudio.PyAudio()
for i in range(pa.get_device_count()):
print(pa.get_device_info_by_index(i))実行します。
pthon3 mic_check.pyRaspberry Pi 4 でリアルタイム推論をしよう
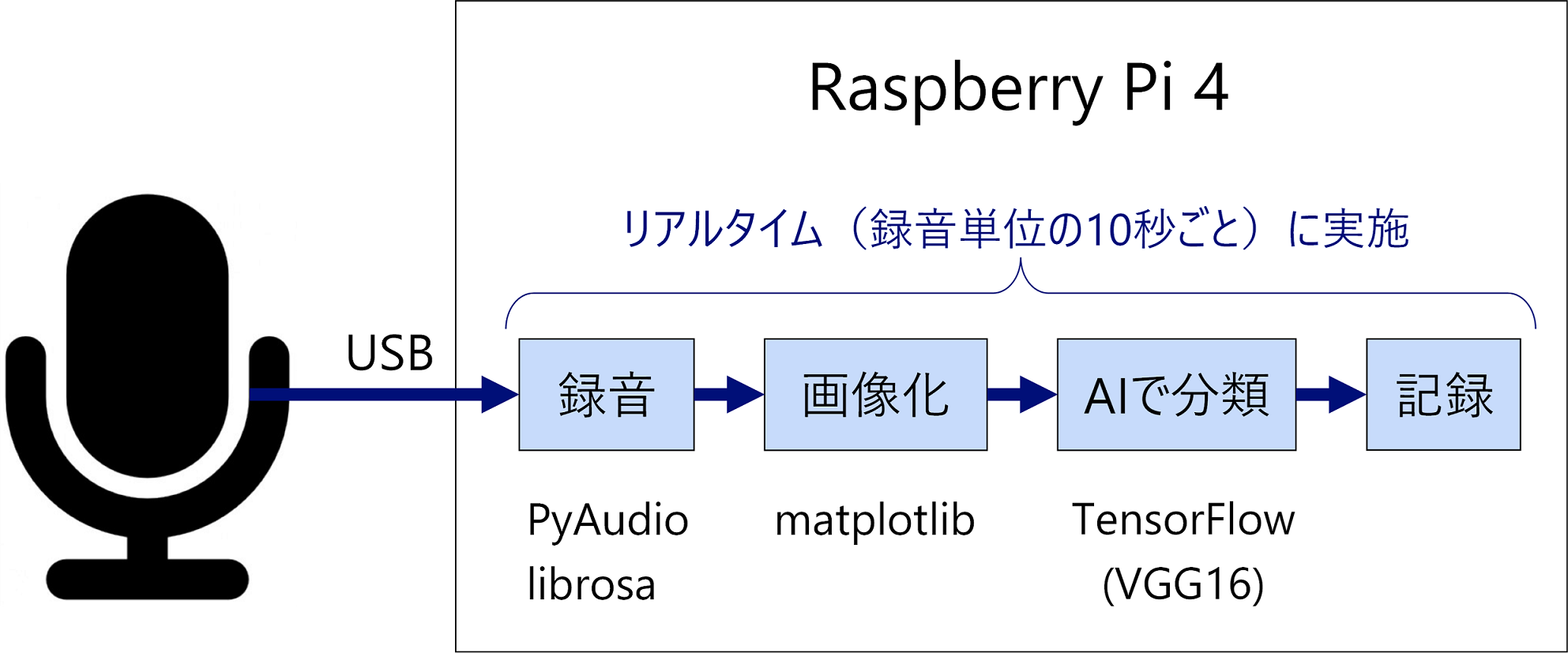
最後に、「AIで救急車のサイレン音を解析し救急車の往来回数をカウントしよう(2)」で作成したVGG16のコードを少し修正し、リアルタイムで(10秒ごとに)録音・画像化・分類するようにしたコードを記述して実行します。前回、PCで学習したfinetuning.h5 というファイルもこちらにコピーする必要があります。
私が作成した finetuning.h5 をここに置いておきます。
以下のようなフォルダ構成にしてください。
推論時のファイル構成
そして save_and_predict.py として以下のコードを作成してください。
import pyaudio
import wave
import numpy as np
import multiprocessing
import time
import os
import sys
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from keras.preprocessing import image
import librosa
import librosa.display
import matplotlib.pyplot as plt
import glob
def save(queue):
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1 ##ここに上で確認したUSBマイクのチャンネル番号を入れる。
RATE = 16000 # 録音は16kHz
RECORD_SECONDS = 10
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
while True:
WAVE_OUTPUT_FILENAME = str(int(time.time())) #ファイル名は記録開始時点のunixtime とする
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
buf = np.frombuffer(data, dtype="int16") # 読み込んだストリームデータを2byteのInt型のリストに分離
frames.append(b''.join(buf[::3])) # 記録するデータを1/3に間引いてリストを結合してフレームに追加
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE / 3) # ヘッダのサンプリングレートを16kHzにする
wf.writeframes(b''.join(frames))
wf.close()
def predict(queue):
#VGG16の初期設定
result_dir = 'results'
img_height, img_width = 150, 150
channels = 3
## VGG16
input_tensor = Input(shape=(img_height, img_width, channels))
vgg16_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
## FC
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
## VGG16とFCを接続
model = Model(vgg16_model.input, top_model(vgg16_model.output))
## 学習済みの重みをロード
model.load_weights(os.path.join(result_dir, 'finetuning.h5'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
while True:
for filename in glob.glob('./*.wav', recursive=False):
#ここからwav ファイルを探してスペクトラムのpng 画像に変換
png_filename = filename.replace(".wav",".png")
y, sr = librosa.load(filename,sr=16000)
n_fft = 2048
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=10000)
librosa.display.specshow(spec, vmin=-100, vmax=-50, sr=sr, x_axis='time', y_axis='log')
plt.axis('off')
plt.subplots_adjust(left=0, right=1, bottom=0, top=1)
plt.savefig(png_filename)
plt.clf()
os.remove(filename)) #wavファイルは削除
#ここからVGG16の推論
## 画像を読み込んで4次元テンソルへ変換
img = image.load_img(png_filename, target_size=(img_height, img_width))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = x / 255.0
## 結果を出力
pred = model.predict(x)[0]
print(pred)
if __name__ == '__main__':
queue = multiprocessing.Queue()
# プロセス生成
p0 = multiprocessing.Process(target=save, args=(queue,))
c0 = multiprocessing.Process(target=predict, args=(queue,))
# プロセス開始
p0.start()
c0.start()
# プロセス終了待ち合わせ
p0.join()
c0.join()実行すると、マイクが10秒ごとに音を拾ってwav ファイルとして保存し、これをフーリエ変換してpng 画像を作り、その画像をVGG16にかけて音響を分類します。
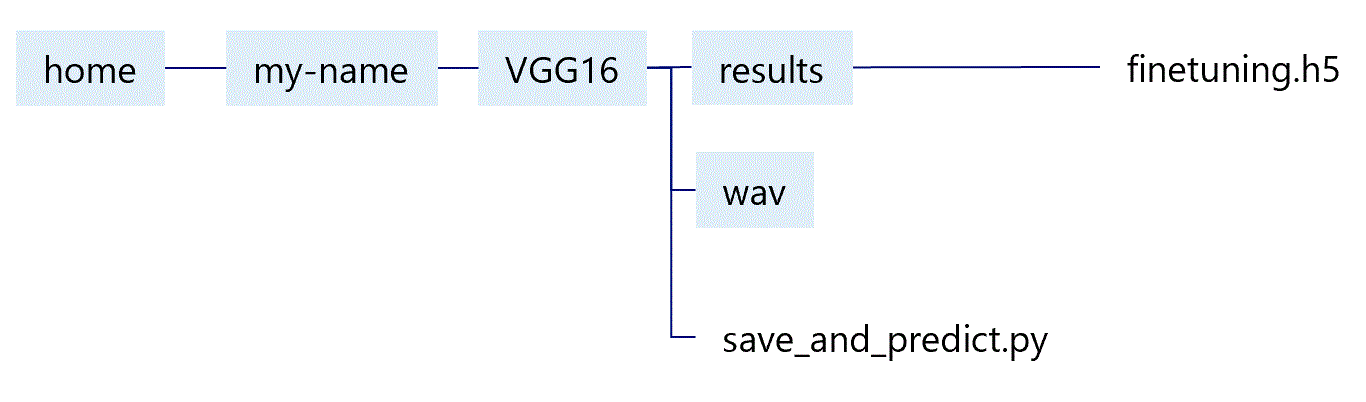
python3 save_and_predict.pyコードの解説
簡単にコードの解説をしますと、以下のようになっています。プログラムを開始した後、プロセス1,プロセス2を起動します。それぞれのプロセスは独立に動作する無限ループになっていて、プロセス1はマイクの音を拾ってwav ファイルを作り続けます。
プロセス2では TensorFlowのVGG16を起動しっぱなしにした上で、wavファイルを見つけたらフーリエ変換してpng 画像ファイルに変え、その画像ファイルをVGG16にかけて画像分類します。その後、分類結果をrecord.txt というログファイルに書き込みます。
結論
以上、TensorFlowによるリアルタイム音響識別機能のついたRaspberry Pi 4 の開発方法の記事でした。ポイントとしては、
- 音響はフーリエ変換した後に画像分類として認識すれば特徴的な音であれば容易に識別可能であること。
- 簡単な画像分類にはVGG16のファインチューニングで対応できること
- VGG16の学習自体はRaspberry Pi 4 ではできないものの、GPUを搭載していない比較的高性能なPCであれば可能であること
- PCで学習したモデル(ここでは finetuning.h5) をRaspberry Pi 4 に移すことで、Raspberry Pi 4でも推論をさせることは可能であること
- Raspberry Pi 4には標準のRaspberry Pi OS (旧称Raspbian OS) ではなくUbuntu を入れたうえでTensorFlow のインストールが必要であること。このためには、4GB以上のメモリを搭載したRaspberry Pi 4が必要であること。
といったところでした。参考になれば幸いです。

