この記事は3回の連載記事です。こちらもご覧ください。
AIで救急車のサイレン音を解析し救急車の往来回数をカウントしよう(1)
AIで救急車のサイレン音を解析し救急車の往来回数をカウントしよう(3)
前回と今回の記事の内容
前回の記事では、我が家の前を救急車が通る数をカウントするため、窓際にマイクとRaspberry pi(ラズパイ)を設置し、2日分の環境音を収集しました。縦軸を周波数ごとの音の強さ、横軸を時間とし、収集した音を画像として可視化したところ、救急車の音・消防車のサイレン音らしき画像の特徴が発見されました。この結果、これらのサイレン音は1日になんと15回以上も記録されており、1回あたり30秒~1分以上も続くことがわかりました。
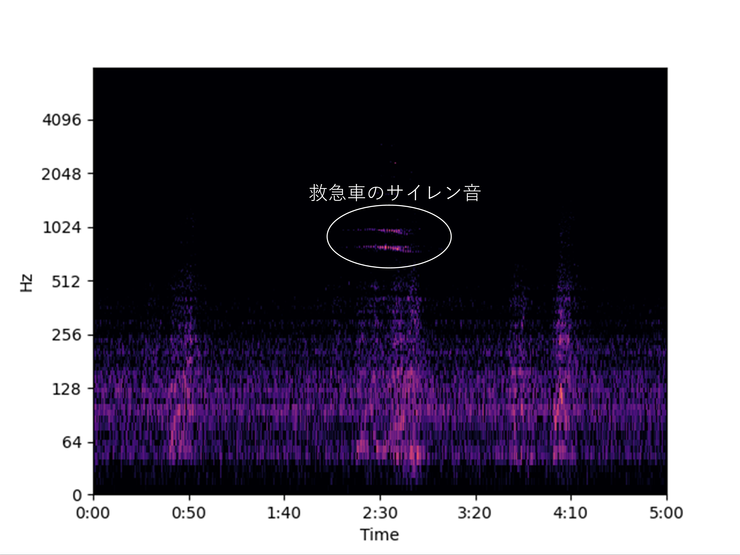
環境音を可視化し救急車のサイレン音の特徴を抽出
今回の記事は、環境音を可視化した画像の特徴をAIに学習させ、人が目で見なくても救急車や消防車のサイレン音を判別できるようにしようというものです。
記事の手順通り進めていけば、特殊なGPUなどを搭載しない普通のWindows PC 1台でAIの学習と推論(※)の両方とも実現できるようになります。
(※学習済みのAIネットワークを使って未知のデータを判定することを「推論」といいます。)
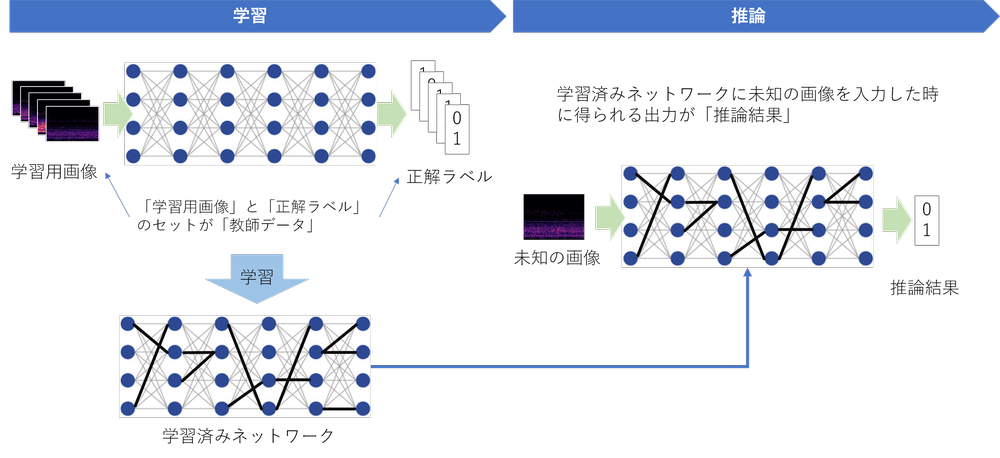
AIの学習・推論・教師データの構造
今回はAIのモデルの中でもVGG16と呼ばれる、画像分類問題でよく利用されるモデルを学習させます。Deep Learning (深層学習)のモデルを学習する際には、一般的に大量の教師データが必要とされます。しかし、VGG16を利用したモデルでは、既存の学習済みモデルをダウンロードし、これを上書きする形で自分で学習させたい画像で再学習する「ファインチューニング」を行うことが簡単にできます。非常に少ない教師データ数でDeep Learningを使った比較的精度の高い画像分類ができるため、実務上非常によく利用されます。
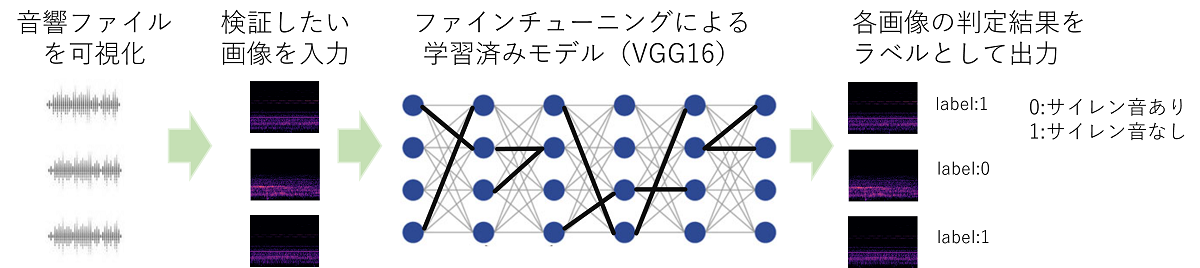
VGG16ファインチューニングを利用した救急車サイレン音有無の分類
AIによる基本的な画像処理の分類
AIによる画像処理は色々なことができます。実写真をアニメ風の画像に変えたり、低解像度の粗い画像を高解像度の詳細な画像に変換したり、人の顔さえ入れ替えたりすることができるようになっています。人の顔の入れ替えなどは、悪い用途しか思いつきませんが。。
しかし、ディープラーニングが登場した初期の頃から研究が進められているのが、「画像分類」「物体検出」「セグメンテーション」といった基本的な処理になります。
画像分類
画像分類は、1枚の写真にラベルを付けるタスクです。例えばイヌの写真とネコの写真があったとき、事前に大量のイヌとネコの写真を学習させておくことで、「この写真はイヌだ」「この写真はネコだ」と分類するようなタスクです。1枚の写真にイヌとネコの両方が映っていたらどうなるって? 確率が半々くらいとして出てくるだけです。

「画像分類」のイメージ
物体検出
物体検出は、1枚の画像の中で学習させた物体がどこに映っているか境界線(バウンディングボックス)で囲って示すことができるものです。1枚の画像の中にイヌとネコが映っていた場合、画像内でイヌが映っている領域の右上の座標は(120,300)、左下の座標は(340,600)ネコの領域の右上は(350,230)左下は(740,670)などと出力することができます。なお画像は通常右上の角を原点(0,0)とし、右方向をX座標,下方向をY座標として表現されます。

「物体認識」のイメージ(画像出所:https://pjreddie.com/darknet/yolov2/)
セグメンテーション
セグメンテーションは、1枚の画像の中で学習させた物体がどこに映っているかピクセル単位で塗分けることができるものです。以下のイメージを見てもらった方がわかりやすいと思います。

「セグメンテーション」のイメージ(画像出所:https://www.esri.com/about/newsroom/arcuser/deep-learning/)
今回のタスクで使う手法は「画像分類」
今回は、一番簡単な画像分類を使うことにしましょう。画像内に、救急車か消防車の音に特徴的な形が含まれていれば0を、含まれていなければ1を出力するようにします。画像分類のアルゴリズムとして冒頭触れたようにVGG16 というモデルを利用します。
可視化画像を作り直す
5分単位の画像を10秒単位の画像にする。目盛りや枠もなくす
前回の記事では、環境音を5分単位のwav音声ファイルとして保存し、そのまま可視化画像に変換したため、1つの画像が5分間の音を表現していました。画像を解析した結果、1回の救急車来訪で30秒から1分半近く救急車のサイレン音が記録され続けていたこともわかりました。
今回は画像分類のAIを使います。画像の中に救急車・消防車のサイレン音が含まれているかいないか、ゼロかイチかで出力します。このため、1つの画像が5分間だと長すぎます。サイレン音が何時何分何秒 ~ 何時何分何秒の間鳴っていたということを記録したいので、10秒単位くらいがちょうど良さそうです。
このため以下ように、もともと5分単位で可視化画像としていたものを10秒単位に作り替えます。さらにAIが画像認識しやすいよう、外側の白い枠や目盛りなどは表示しないようにします。
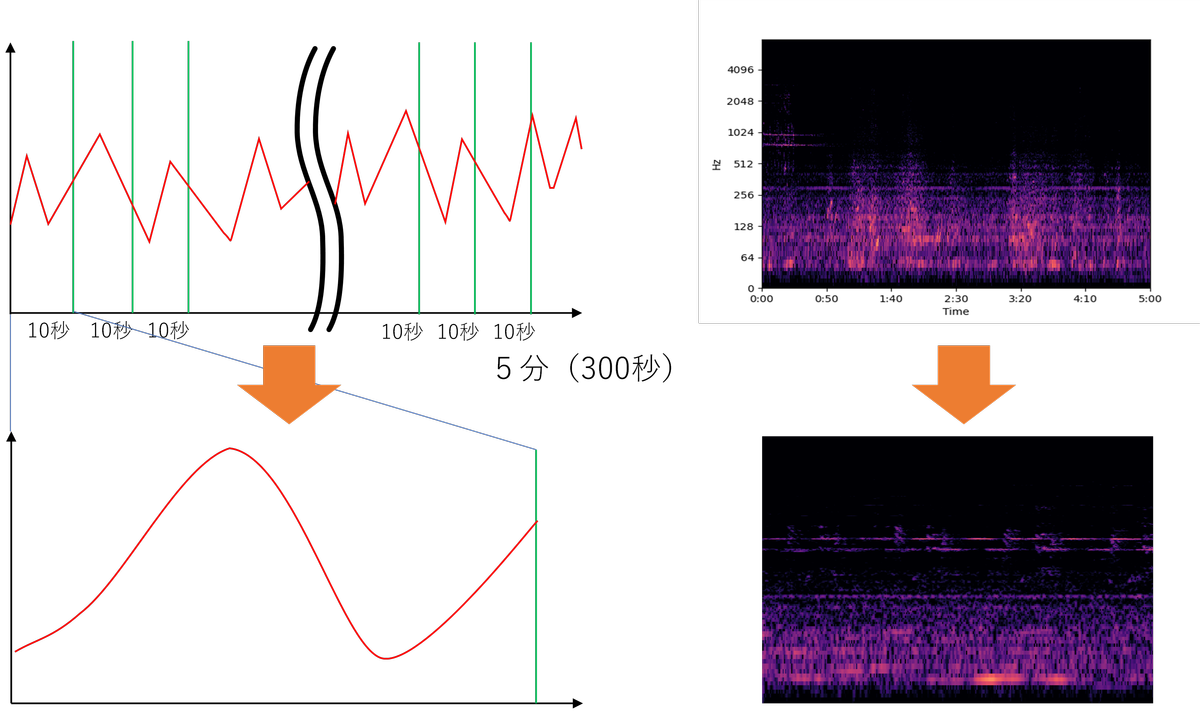
音声の可視化スケールを変更・目盛なども削除
以降、以下の2ステップで5分区切りのwav ファイルを10秒区切りの可視化画像に変換していきます。
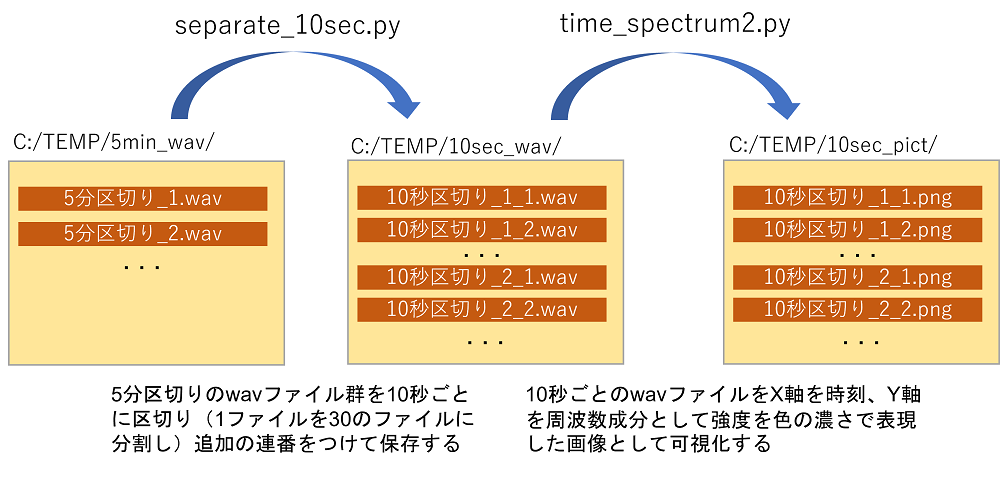
wavファイルの分割&可視化のステップ
5分ごとに記録したwavファイルを10秒単位のwavファイルに分割するプログラム
C:\TEMP\5min_wav\の中に5分ごとに収録した環境音の wav ファイルを保存し、C:\TEMP\の中に(どこでもいいですが)、separate_10sec.py というファイルを作り、以下のコードをコピー・ペーストしてください。
import wave
import struct
import math
import glob
import os
from scipy import fromstring, int16
# 出力用フォルダ作成
file = os.path.exists("C:/TEMP/10sec_wav/")#5分間のwavファイルを10秒ごとに区切って
if file == False:
os.mkdir("C:/TEMP/10sec_wav/")
def cut_wav(filename,time):
print(filename)
# ファイルを読み出し
input_wave_file = wave.open(filename, 'r')
# waveファイルの諸元読み出し
ch = input_wave_file.getnchannels()
width = input_wave_file.getsampwidth()
frame_rate = input_wave_file.getframerate()
frame_number = input_wave_file.getnframes()
total_time = 1.0 * frame_number / frame_rate
integer = math.floor(total_time) # 小数点以下切り捨て
extracted_frames = int(ch * frame_rate * time)
num_cut = int(integer//time)
# wavの実データを取得し、数値化
data = input_wave_file.readframes(input_wave_file.getnframes())
input_wave_file.close()
X = fromstring(data, dtype=int16)
wavf = os.path.splitext(os.path.basename(filename))[0] #フルパス・拡張子なしのファイル名作成
for i in range(num_cut):
print(i)
# データを切り出し
start_cut = i * extracted_frames
end_cut = i * extracted_frames + extracted_frames
Y = X[start_cut:end_cut]
output_data = struct.pack("h" * len(Y), *Y)
# ファイルに書き出し
out_filename = 'C:/TEMP/10sec_wav/'+ wavf + "_" + str(i) + '.wav'
output_wave_file = wave.open(out_filename, 'w')
output_wave_file.setnchannels(ch)
output_wave_file.setsampwidth(width)
output_wave_file.setframerate(frame_rate)
output_wave_file.writeframes(output_data)
output_wave_file.close()
def main():
f_names = glob.glob("C:/TEMP/5min_wav/*.wav")#5分ごとに保存されたwav ファイルを置いておく場所
for f_name in f_names:
cut_wav(f_name,10)
if __name__ == "__main__":
main()コマンドプロンプトから実行します。
python separate_10sec.pyC:\TEMP\10sec_wav\の中に10秒単位で区切られたwavファイルが連番で保存されます。
10秒単位のwavファイルを可視化するプログラム
今度はこのwavファイルを可視化します。前回の記事で可視化した際に利用したプログラムとほとんど同じですが、AIが学習・推論しやすくするため、軸の目盛や外側の白枠を描画しないように設定を変更しています。
C:\TEMP\の中に(どこでもいいですが)、time_spectrum2.py というファイルを作り、以下のコードをコピー・ペーストしてください。
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
import glob
import os
# 出力用フォルダ作成
file = os.path.exists("C:/TEMP/10sec_pict/")#5分間のwavファイルを10秒ごとに区切って
if file == False:
os.mkdir("C:/TEMP/10sec_pict/")
files = glob.glob("C:/TEMP/10sec_wav/*.wav")
for file in files:
print(file)
file_name = os.path.basename(file)
if os.path.exists("C:/TEMP/10sec_pict/" + file_name.replace(".wav",".png")):
pass
else:
y, sr = librosa.load(file,sr=16000)
n_fft = 2048
spec = np.abs(librosa.stft(y, hop_length=512))
#spec = librosa.amplitude_to_db(spec, ref=np.max)
spec = librosa.amplitude_to_db(spec, ref=10000)
librosa.display.specshow(spec, vmin=-100, vmax=-50, sr=sr, x_axis='time', y_axis='log')
plt.axis('off') #軸の目盛を表示させない
plt.subplots_adjust(left=0, right=1, bottom=0, top=1)#外側の余白を表示させない
plt.savefig("C:/TEMP/10sec_pict/" + file_name.replace(".wav",".png"))
plt.clf()コマンドプロンプトから実行します。
python time_spectrum2.pyこれを実行すると、1日分だけでも 24時間×60分×6 = 8540ファイルもの画像が出力されることになります。寝る前にプログラムを走らせてから一晩放置しておけば翌朝には全部の画像が出力されていることでしょう。
10秒単位で作成した可視化画像を眺めてみる
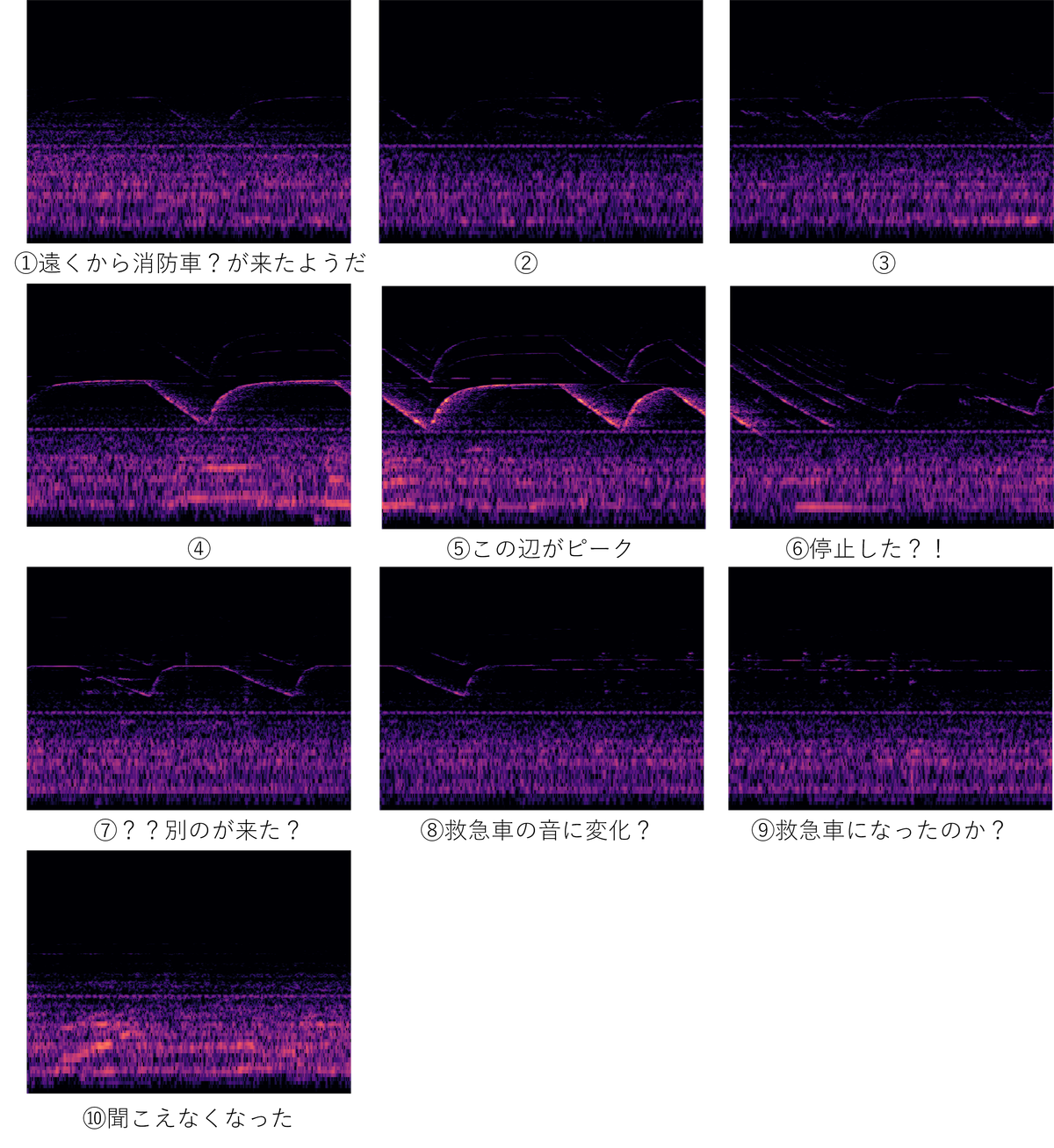
まず救急車のサイレンと思われる画像を見てみましょう。1枚が10秒ですので、このケースでは音開始から終了まで70秒間近く救急車のサイレンが鳴り響いていたというケースです。
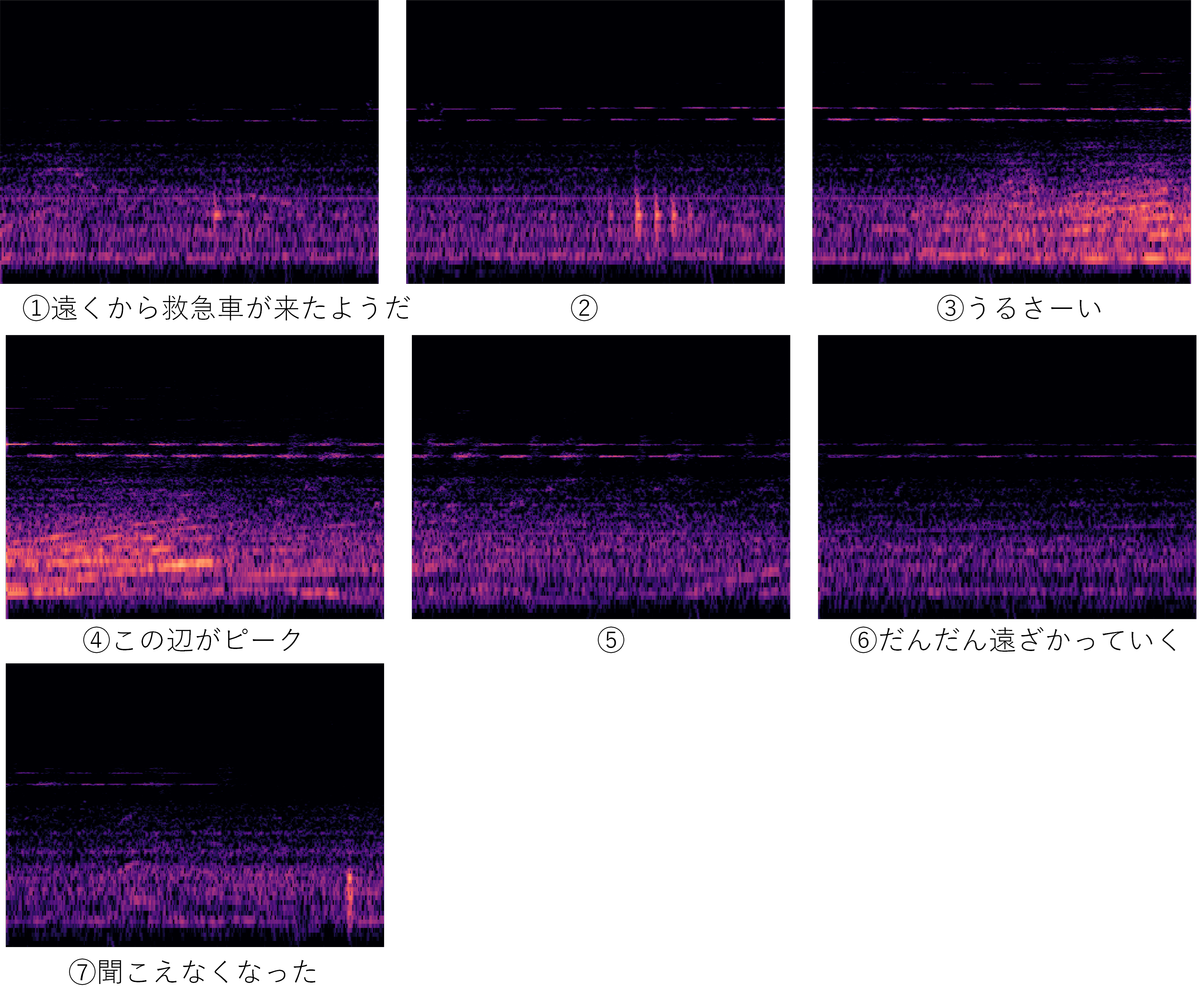
救急車のサイレン音の開始から終了まで
上記の画像の中で①、⑦の部分を拡大した画像と、その部分の元になった音を以下に載せます。人間の耳に辛うじて聞こえ始めた時点とほぼ一致するタイミングで画像上にもサイレンを表す薄い線が出現していることがわかります。
救急車サイレン音の鳴り始め:①の部分の拡大図
この画像の元になった実際の音↓
救急車サイレン音の鳴り終わり:⑦の部分の拡大図
この画像の元になった実際の音↓
繰り返しですが人間の耳に辛うじて聞こえ始めた時点とほぼ一致するタイミングで画像上にもサイレンを表す薄い線が出現していることがわかります。
あとは、AIがこの薄い線を(もちろんピーク時の濃い線も)きちんと認識できれば、遠くの救急車のかすかなサイレン音でもAIがきちんと認識できるということになります。
他にも消防車の音だと以下のような形になりました。救急車と線の出方が全く異なりますが、折角なのでこれもサイレン音とカウントすることにしましょう。
消防車のサイレン音の開始から終了まで
上の10枚の画像(=100秒分)の消防車のサイレン音が以下になります。こんな感じで可視化されるんだ、、というのが見えてくるようになります。そのうち画像を見ただけで逆に音が想像できるようになりそうですね。実のところコンピュータを使えば、逆フーリエ変換をするだけなので、画像から実際に音を再現することは可能です。
AI(VGG16)に学習させるための教師データを作成する
ようやくAI(VGG16)に学習させるデータの準備ができました。このような非常に簡単な実験であっても、ここに至るまでのプロセスで心が折れそうになりますが、全体でいえばまだ5合目です。しかも10合目まで行ってみないと、実際に機能するかどうかわからない、というのがDXの一つの特徴です。SI事業者からみれば、このような案件の請負契約はリスクが高いので、逃げ出すか高いリスクプレミアムを乗せた見積りを発行するしかありません。よほど間抜けで大金持ちの大企業以外は、自分で勉強してDXを内製化すべき理由がこのあたりにあります。
話を戻しましょう。
教師データを入れるフォルダを作成する
Cドライブの下に以下のようなフォルダ構成を作成してください。

教師データを入れるフォルダ構成
train, validation 以下にそれぞれsiren, no-siren というフォルダがありますが、この中に教師データを入れます。validation フォルダに入れるデータは、AIの学習中に、どの程度正確に推論できるようになったかチェックするため専用のデータです。直接学習には利用しませんが、正解がわかっているデータなので「教師データ」の一部です。
なお、finetuning.py, predict.py はこの後作るpython のプログラムです。
教師データをフォルダに投入する
今回のモデルではフォルダの名前(siren, no-siren)がそのまま「正解ラベル」となっています。siren の中には救急車・消防車のサイレンが鳴っている時の画像を入れてください。no-siren の中には救急車・消防車のサイレン音がない通常時の画像を入れてください。
※こから先は、実際に救急車・消防車のサイレン音を含む音声ファイルを画像にしたデータがないと進めません。私のように救急病院の近くにお住まいでないかぎり、そのようなデータを簡単に用意できる人はそれほど多くないことと思います。ただ、AIの実験として試してみたい場合は、例えばイヌとネコの画像をそれぞれ250枚ずつ集めてきて試してみると良いと思います。
私の場合、 C:/TEMP/data/train/siren の中に救急車・消防車が来た時の音を可視化した画像200枚、C:/TEMP/data/train/no-siren の中に何も来ていない時の画像を200枚入れました。また、C:/TEMP/data/validation/siren と C:/TEMP/data/train/no-siren
の中にそれぞれ同じ条件でtrain に入れたものとは別の画像を50枚ほど選んで入れました。
冒頭触れた通り、今回は別のデータで学習したVGG16というAIモデルを今回新しく投入した上記のデータで再学習(ファインチューニング)しますので、この程度の教師データ数でも十分な精度が出る、という仕掛けになっています。
過去の経験では、イヌ、ネコ、馬、羊など動物10種類をそれなりの分類ができるようになるためには、train には各種類ごとに30枚、validation には10枚くらい入れておけば、一応AIとしての分類は機能しました。AIを実務に使う際にはこのようなノウハウが非常に重要になってきます。このようなノウハウは大抵どこにも書かれていないので自分でやってみるしかありません。このサイトでは、このようなノウハウをなるべく公開していきたいと思います。
VGG16をファインチューニングする
tensorflow をインストールする
Windows に python はもう入っていますね? 入っていない場合はこことかここを参考にインストールしてください。
次にtensorflow をインストールします。tensorflow とはGoogleが開発した機械学習のライブラリです。他のライブラリ同様python のプログラムの中に import して利用します。tensorflow を使ったコードの書き方は勉強していくと果てしなく深淵な世界が広がっていますので専門のサイトに譲ります。
このサイトの趣旨は、手作りでAIを学習させ、ちょっとだけカスタマイズして色々な用途に広げていくというコンセプトなので、まずはインストールして、コードをコピーして動かしてみてください。

前置きが長くなりましたが、インストールの方法は簡単です。
pip install –-upgrade pip
pip install --upgrade tensorflowコードをコピーして実行する
C:/TEMP/ の中に finetuning.py というファイルを作り、以下のpython のコードを張り付けてください。VGG16モデルをファインチューニングするためのコードになります。
import os
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from tensorflow import keras
from tensorflow.keras import optimizers
import numpy as np
img_width, img_height = 150, 150
train_data_dir = 'C:/TEMP/data/train'
validation_data_dir = 'C:/TEMP/data/validation'
nb_train_samples = 200
nb_validation_samples = 50
nb_epoch = 15
result_dir = 'results'
def save_history(history, result_file):
loss = history.history['loss']
acc = history.history['accuracy']
val_loss = history.history['val_loss']
val_acc = history.history['val_accuracy']
nb_epoch = len(acc)
with open(result_file, "w") as fp:
fp.write("epoch\tloss\tacc\tval_loss\tval_acc\n")
for i in range(nb_epoch):
fp.write("%d\t%f\t%f\t%f\t%f\n" % (i, loss[i], acc[i], val_loss[i], val_acc[i]))
if __name__ == '__main__':
file = os.path.exists("C:/TEMP/results/")#結果保存用のディレクトリを作る
if file == False:
os.mkdir("C:/TEMP/results/")
input_tensor = Input(shape=(img_height, img_width, 3))
#ネット上から imagenet の学習済みモデルをロードする。→初回学習時は30分もかかることがあるがこの部分が原因。また Fully-connected層(FC)はいらないのでinclude_top=False)
vgg16_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# FC層を構築
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
model = Model(vgg16_model.input, top_model(vgg16_model.output))
print('vgg16_model:', vgg16_model)
print('top_model:', top_model)
print('model:', model)
# layerを表示
for i in range(len(model.layers)):
print(i, model.layers[i])
# 最後のconv層の直前までの層をfreeze
for layer in model.layers[:15]:
layer.trainable = False
model.summary() #モデルの構造をコマンドラインに表示
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
train_datagen = ImageDataGenerator(
rescale=1.0 / 255, #RGB(0〜255)で読み込まれた各画素のRGB値を0.0〜1.0の間に収まるように正規化する。これは必須。
shear_range=0.2, #斜めに引き延ばすような画像変換を行い学習画像を水増しする。今回はなくても良い
zoom_range=0.2, #拡大縮小変換を行い学習画像を水増しする。今回はなくても良い
horizontal_flip=True #左右反転を行い学習画像を水増しする。今回はなくても良い
)
test_datagen = ImageDataGenerator(rescale=1.0 / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=2,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=2,
class_mode='binary')
# Fine-tuning
history = model.fit(
train_generator,
steps_per_epoch=nb_train_samples ,
epochs=nb_epoch,
validation_data=validation_generator,
validation_steps=nb_validation_samples)
model.save_weights(os.path.join(result_dir, 'finetuning.h5'))
save_history(history, os.path.join(result_dir, 'history_finetuning.txt'))
早速、AI(VGG16)の「学習」をしてみましょう。
python finetuning.pyいろいろ表示が出てきますね。
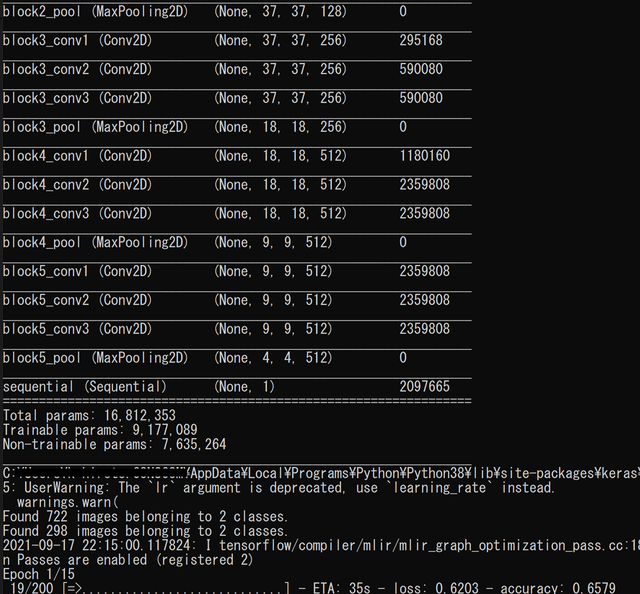
上記のVGG16学習用コードの進捗表示画面
1Epoch の学習が50秒弱で終わります。1Epoch というのは、投入した教師データを全部使って1まわし学習させる、という意味です。このコードでは15Epoch で止めることにしていますので、GPUなど搭載していない通常のPCでも12~13分で学習が済むはずです。
results フォルダの中に finetuning.h5 というファイルが出力されていると思いますが、これが学習済みネットワークの本体になります。
VGG16で推論してみる
推論用のプログラムを準備する
C:/TEMP/の中に predict.py というファイルを作成して以下のコードを貼り付けてください。
import os
import sys
from keras.applications.vgg16 import VGG16
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from keras.preprocessing import image
import numpy as np
if len(sys.argv) != 2:
print("usage: python predict.py [filename]")
sys.exit(1)
filename = sys.argv[1]
print('input:', filename)
result_dir = 'results'
img_height, img_width = 150, 150
channels = 3
# VGG16
input_tensor = Input(shape=(img_height, img_width, channels))
vgg16_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# FC
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
# VGG16とFCを接続
model = Model(vgg16_model.input, top_model(vgg16_model.output))
# 学習済みの重みをロード
model.load_weights(os.path.join(result_dir, 'finetuning.h5'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 画像を読み込んで4次元テンソルへ変換
img = image.load_img(filename, target_size=(img_height, img_width))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = x / 255.0
# 結果を出力
pred = model.predict(x)[0]
print(pred)そして実行します。
python predict.py C:/TEMP/hogehoge.pngC:/TEMP/hogehoge.png の部分は推論したい画像のパスにそれぞれ書き換えてください。
絶対パスで書いても相対パスで書いても構いません。
すると、以下のような結果が出力されます。
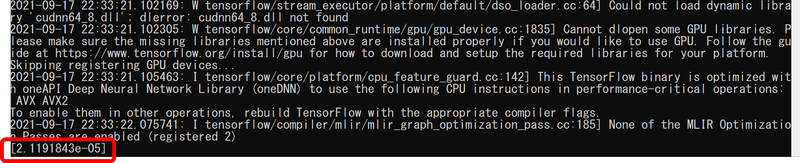
上記のVGG16の推論結果画面
何やら警告メッセージなどが出ていますが、結果は最後の行の[2.1191843e-05] です。べき数表記になっていて一見わかりにくいですが、2. 1191843×10^(-5)という意味ですから、0.000021191843です。出力結果はほぼ「ゼロ」であったと解釈してよいですね。
今回のAIモデルは、救急車もしくは消防車のサイレン音が含まれていれば0(ゼロ)、含まれていなければ1(イチ)を出力します。つまり0.5より小さければサイレン音が含まれていると解釈できると思います。
画像ごとに推論結果を表示してみる
サイレン音が含まれている画像の推論結果
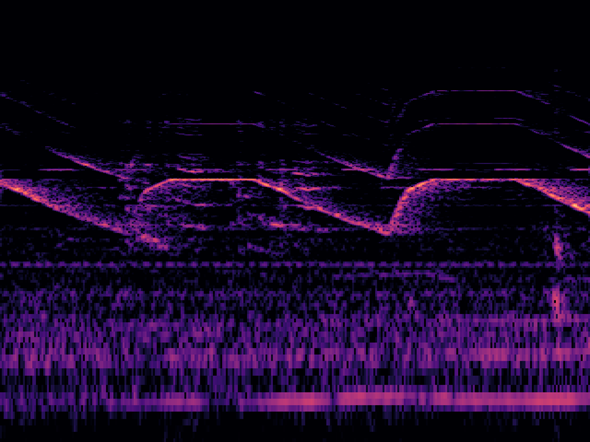
推論した画像(1)
消防車と救急車の音の盛大なコンボという状況です。発狂するほどうるさい状況です。
推論結果は0.00036749 でほぼゼロです。当然正解。
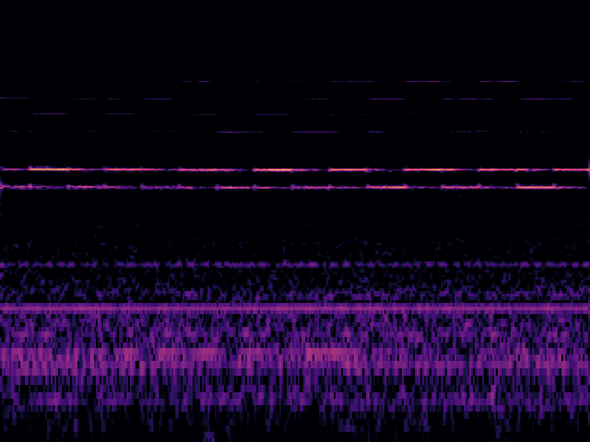
推論した画像(2)
救急車が家のすぐ前を走っている状況です。うるせーー!
推論結果は 8.654434e-07 でほぼゼロです。正解。
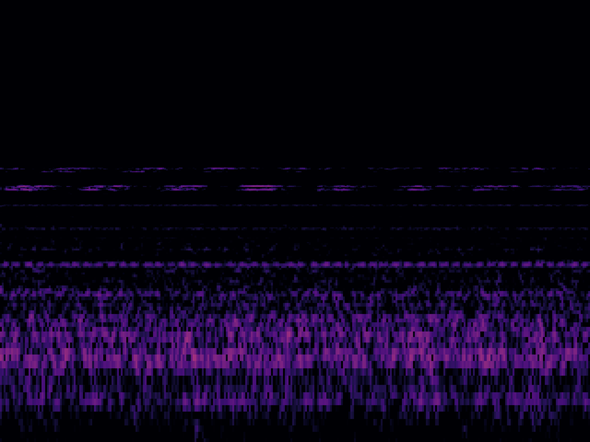
推論した画像(3)
結果:1.3585744e-05
少し小さい音の場合でもほぼ「ゼロ」という結果です。正解!
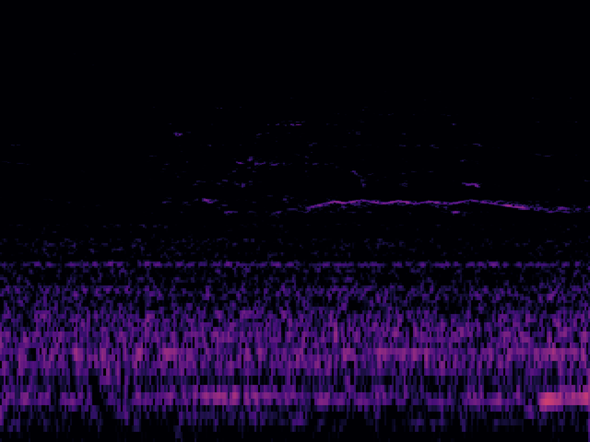
推論した画像(4)
消防車の音が途中からかすかに聞こえ始める、というきわどい状況です。
推論結果は、0.00233001。 これもほぼゼロです。大正解!!!
サイレン音が含まれていない画像の推論結果
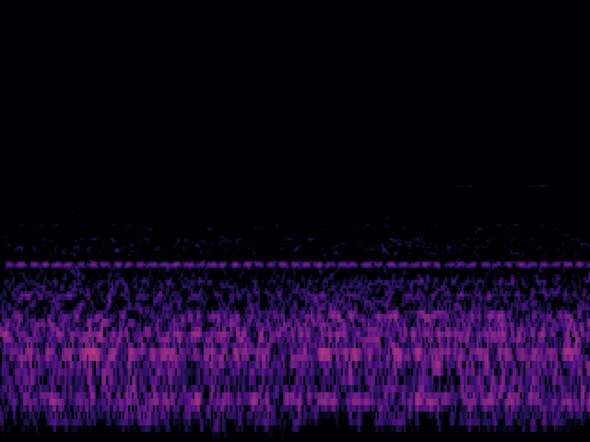
推論した画像(5)
一般車の走行音も含めてほぼ静寂、といった状況。
推論結果は、0.9571738。ほぼ「イチ」なので正解。
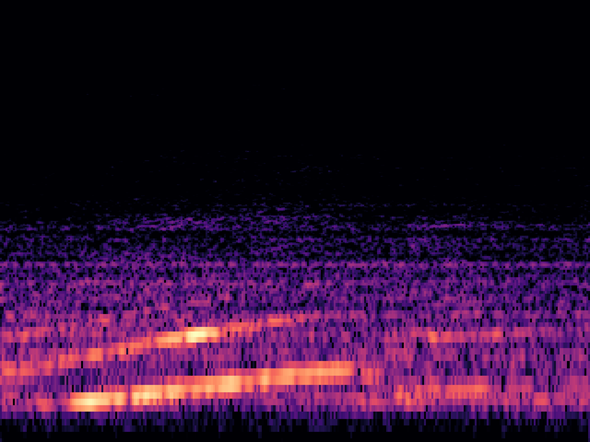
推論した画像(6)
ランボルギーニでしょうか? 車のものと思われる急加速音が含まれていますが救急車や消防車のサイレン音ではないです。
推論結果は、0.9309739。ほぼ「イチ」なので正解。
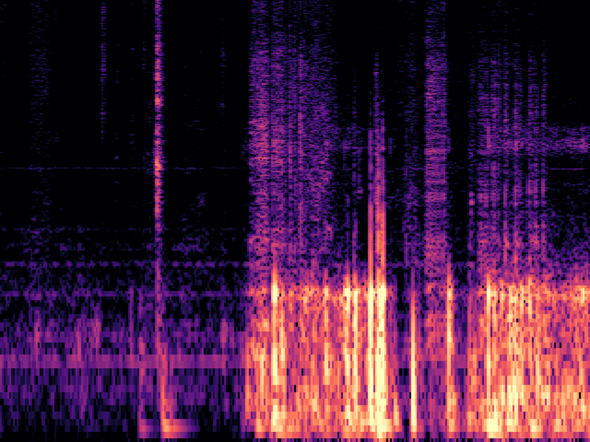
推論した画像(7)
マイクをセットして部屋から出た際に扉を閉めた際のノイズが記録されている部分。
推論結果は 0.97060674。ほぼ「イチ」なので正解。
たった500枚の画像で学習しただけなのに、完璧に識別できるモデルになっているではありませんか。
まとめ
今回、救急車・消防車のサイレン音を10秒ごとに可視化した画像をAIのモデルに学習させました。AIのモデルはVGG16という「画像分類」ではよく利用されるモデルを利用し、既存の学習済みモデルの一部を、独自の画像で再学習させる「ファインチューニング」という手法を使いました。教師データとしては、サイレン音を含む画像250枚(トレーニング用200枚、検証用50枚)、サイレン音を含まない画像250枚(トレーニング用200枚、検証用50枚)を用意し、AIの計算使えるGPUを搭載していない普通のPC学習させたところ10分ほどの学習時間で、ほぼ間違いない判定ができる素晴らしいモデルができました。
サイレン音を可視化した画像には、500Hzより上の音域に細い線が現れるかどうかなので、本当に判定できるか少し不安ではありましたが、AIにとってはこの程度は朝飯前のようです。考えてみれば、昨今のAIモデルは、パピヨンとチワワの違いを平気で分類してしまうので「明確に線が出ている」といった特徴があれば簡単なことなのかもしれません。400Hzより下の音域には自動車の走行音や何もない状態の騒音が記録されています。この音域に混ざる特徴的な音響を学習させたときに、判定できるかどうかが興味深いです。
今回はraspberry pi(ラズパイ)で録音した音をPC上で学習・推論させてみました。
次回はraspberry pi上でリアルタイムに録音→推論するという、ハードウェア的にも時間的にもギリギリを攻めてみようと思います。
テレビ会議・オンラインセミナーのスライドをAIが自動スクショするPCソフト
最後に少しだけ宣伝をさせてください。
テレビ会議やオンラインセミナーでスクショ撮りに忙しかったことはありませんか?
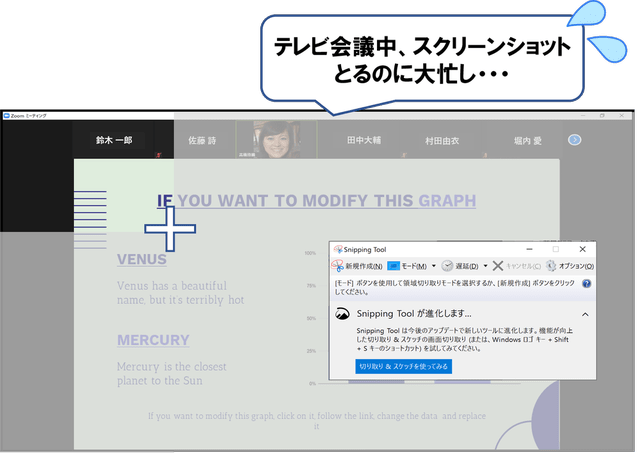
Summary Shots は、弊社 Tokyo Properties で開発したPCアプリケーションです。
AIが画面の変化を自動で検知してpngフォーマットのスクショを撮ってくれるので、会議中にマウスでスクショをとってファイル名を付けるといった作業から完全に開放されます。同時にmp3で音声も録音してくれます。さらに付属の再生ソフトでスクショ画像と音声を同期し、最大4倍速で再生することができるため、会議の振り返りも短時間にできます。

Summary Shotsの動作イメージ
ZOOM、Teams、YouTube Live などどのような会議システムにも対応しています。
無料体験版もありますので、ぜひお試しください。


