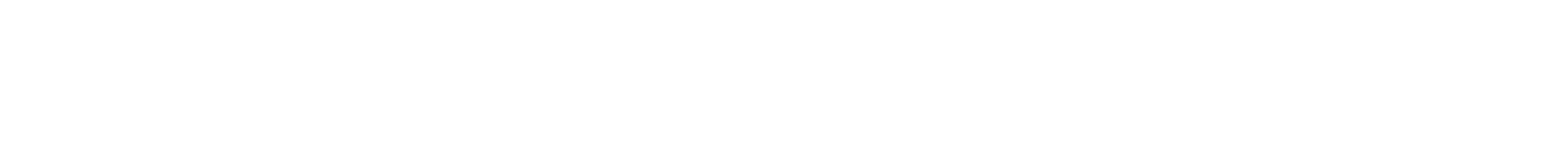
今回のお題「スクショ画像をFESSで検索」
「画像を検索する」というとGoogleの画像検索をイメージする人が多いでしょうか? インターネット上での画像の検索は、通常、Webサイト上の画像周辺の文章を検索して画像を拾ってくるものです。
しかし、今回ご紹介したいのはそういう検索ではありません。大量のスライドのスクショ画像を抱えてしまった人に最適な検索方法の紹介をしたいと思います。コロナのせいで会議のたびにZOOMのスクショ画像が増えていく、という人が増えていると思います。もちろんスライドのスクショ画像でなくても構いません。文字が書きこまれた「画像ファイル」を大量に持っている人であれば役に立つと思います。
先に今回の企画で何をするか図示すると、以下のフローのようなことをします。

今回のタスクフロー
画像保存魔の検索ニーズ
この世には保存魔のような人がいます。私もその一人ですが、紙の本は片っ端からスキャンしてpdf形式で保存していますし、会議のスクショも後述するSummary Shots を使って、会議のスライドはほとんど png形式でPCに保存しています。
おかげ様で所蔵していた数百冊の本が今ではAndroidスマホ1台の中に収まり、読みたい時にいつでも読めます。また、会議中にエライ人が「あの時のあの資料があれば・・・」などと言い出したらすぐさま『あッ、偶然スクショしていました!』とか言って「確かこれでしたっけ?」などとドラえもんのように取り出したりします。
ええ、もちろん実際には全てのスライドをスクショしてますよ。ストレージの単価はどんどん安くなっているんですからスクショ画像程度は全部手元に持っておけばいいんです。
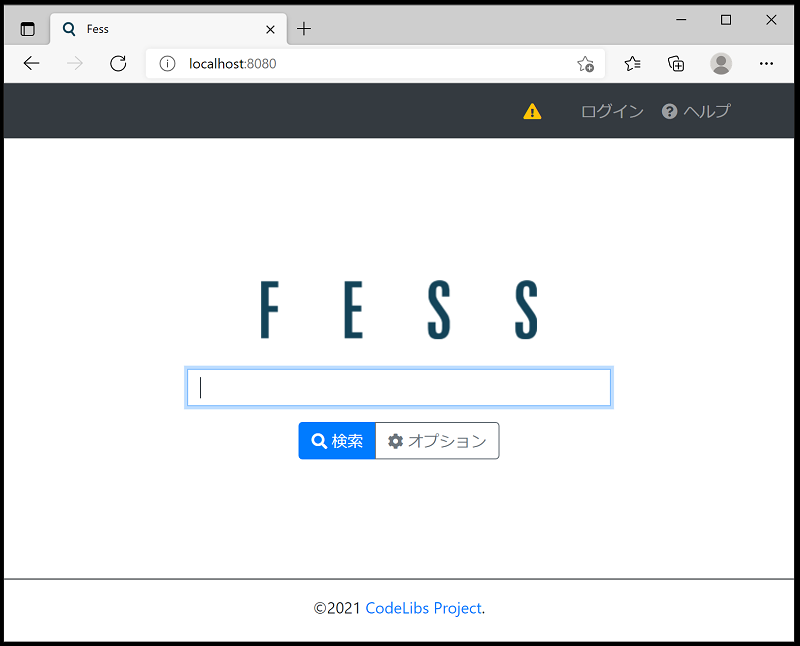
PDF化した蔵書でいっぱいの筆者のスマホ
しかし、そんな保存魔もSummary Shotsでスクショを撮った会議数が過去半年間で200回近くになり、スクショ画像が12000枚超(容量はわずか6Gバイトほどですが)になってしまうと、さすがに目的の資料を簡単に探し出すのが難しくなってきました。
そこで、今回はこの大量のスクショ画像をFESSという検索エンジンを使って検索できる状態にしてしまおう、という企画になります。
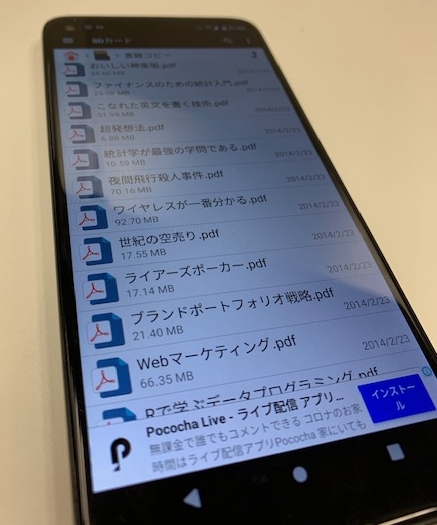
スクショ画像が詰まった筆者のミーティングフォルダ
オンライン会議のスクショと録音をするSummary Shots
話が前後してしまいましたが、オンライン会議、オンラインセミナーをAIが自動でスクショ&録音をするSummary Shots を紹介させてください。弊社 Tokyo Properties で開発した Windowsアプリケーションです。AIが画面の変化を自動で検知してpngフォーマットのスクショを取ってくれるので、会議中に手でスクショをとってファイル名を付けるといった作業から完全に開放されます。同時にmp3で音声も録音してくれます。
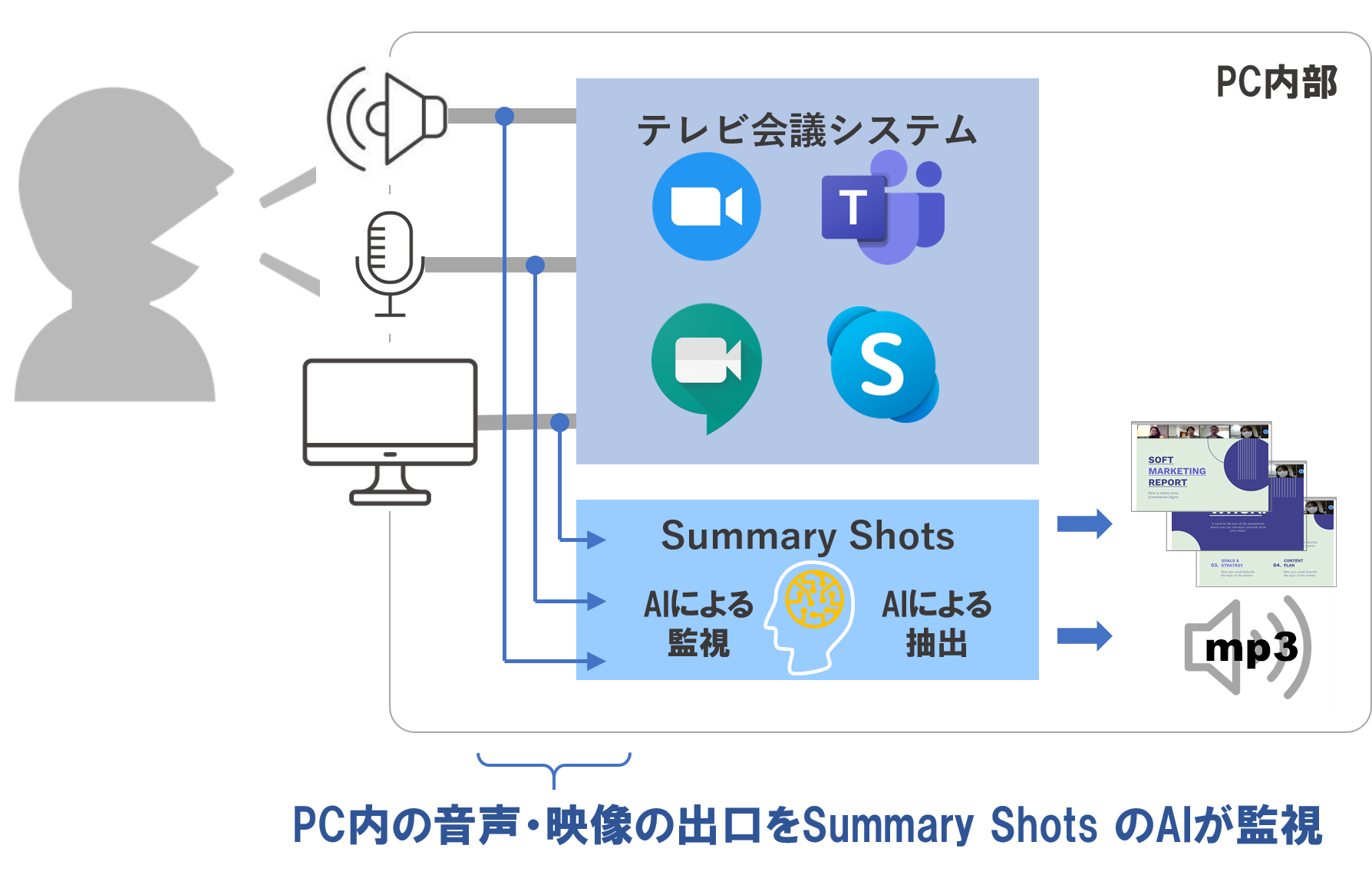
Summary Shotsの動作原理
Summary Shotsにはもう一つ素晴らしい点があります。付属の再生ソフトでスクショ画像と音声を同期し、最大4倍速で再生することができるため、会議の振り返りも短時間にできます。発言者の声色の部分まで内容をリアルに振り返ることができるので、時間がある若者なら復習しておくことで「キレキレ」の発言ができるようになりますし、スクショしたデータは永遠に消えませんので、数か月~1年経っても鮮明な記憶の一部として取り出すことができるようになります。ビジネスマンの秘密兵器としてご活用ください。こちらのページからSummary Shotsの無料版トライアル版をダウンロードいただけます。

Summary Shotsの動作イメージ
画像をPC内で文字起こしし、そのまま画像にテキストを埋め込む
まず問題になるのは、手元に持っている大量のスクショ画像には何の説明文もついていないことです。無理やりにでも説明文をつけてしまわないとFESSで検索できる状態にはなりません。幸い元々スライドとして作られたものをスクショした画像なので、大きめの文字が映っているはずです。これをOCRして文字起こししましょう。
いやさ、お役人が作るスライドはスクショしても文字が潰れて読めないよ。こういうのは対象外かな・・・

お役人の資料
今回もpython を使って、スクショ画像をOCRします。python を使ってPC内で、無料でOCRするための設定方法については、こちらの記事をご確認ください(TesseractというOCRエンジンとpyocr というpython のラッパーをインストールしておいてください)。
その上で、以下のコードをコピペして実行します。
# coding: utf-8
"""
コマンドプロンプトで
>python png_info_embed.py フォルダのフルパス
と入力すると、当該フォルダ以下のすべてのpng画像をOCRしてテキストをメタデータ部分に埋め込む
"""
import os
import sys
import re
import pyocr
from PIL import Image
from PIL.PngImagePlugin import PngImageFile, PngInfo
#インストールしたTesseractを環境変数「PATH」へ追記 (もし事前に設定していれば以下の2行は不要)
path='C:\\Program Files\\Tesseract-OCR'
os.environ['PATH'] = os.environ['PATH'] + path
def ocr(path):
tools = pyocr.get_available_tools()
tool = tools[0]
img = Image.open(path)
print(path) #進捗確認用
targetImage = PngImageFile(path) #すでにMy_Textという文字列を含むテキストが埋め込まれていないか確認
if("My_Text" in targetImage.text):
print("This picture already has embeded text.")
else:
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
ocr_text = tool.image_to_string(img, lang="jpn", builder=builder)
ocr_text = " ".join(ocr_text.replace("\n","").split())#テキスト中の改行を削除、複数のスペースがある場合一つにまとめる
output_text = ocr_text
targetImage = PngImageFile(path) #以下の4行でpng画像にテキストを埋め込み上書き保存
metadata = PngInfo()
metadata.add_itxt("My_Text", output_text)
targetImage.save(path, pnginfo=metadata)
print("Text embed finished.")
def file_check(path): #フォルダ内部を再帰的にチェックし、png ファイルがあればOCRをかけてテキスト出力する。
if os.path.isdir(path):
files = os.listdir(path)
for file in files:
file_check(path + "\\" + file)
else:
if path[-4:] == '.png':
ocr(path)
if __name__ == "__main__":
args = sys.argv
file_check(args[1])コマンドプロンプトでpng_info_embed.py が保存されているフォルダに移動して、python を実行します。
C:\TEMP\search_test にpng_info_embed.py が入っていて、C:\TEMP\search_test\targetにpng画像が入っているとすると、以下のように入力してください。

OCR-埋め込みpythonコードの実行
このコードの中では、指定されたフォルダの中のpng 画像を片っ端から見つけて、まだテキストが埋め込まれていなければOCRで文字起こしし、そのテキストをpng 画像の中に埋め込み上書き保存するという処理をしています。
「画像の中にテキストを埋め込む」という部分は他ではあまり聞かない特殊な処理です。png画像ファイルのフォーマットには以下のように画像データ本体の他に「メタデータ」としてテキスト情報を格納する部分が用意されています。

pngファイルの構造概要
このメタデータ部分は撮影条件(撮影地点の緯度経度や、カメラの種類、レンズの種類)などを格納することが想定用途だと思いますが、今回はこの領域を利用して、文字起こししたテキストを埋め込んでしまっている訳です。今回利用する検索エンジンのFESSは大変優秀なので、このメタデータ部分も文章検索の対象としてクロールしてくれるのです。
処理が終わったスクショ画像(png画像)のメタデータ部分に、本当にOCRで文字起こししたテキストが埋め込まれれているかどうか確認してみましょう。秀丸のようなテキストエディタに処理が終わったスクショ画像(png 画像)をドラッグ&ドロップするだけです。なお、テキストエディタで開いた際に全体が文字化けして1文字もそれらしい結果が表示されない場合はSHIFT-JISなど間違った文字コードで開いているかもしれません。文字コードをUTF-8に設定してください。
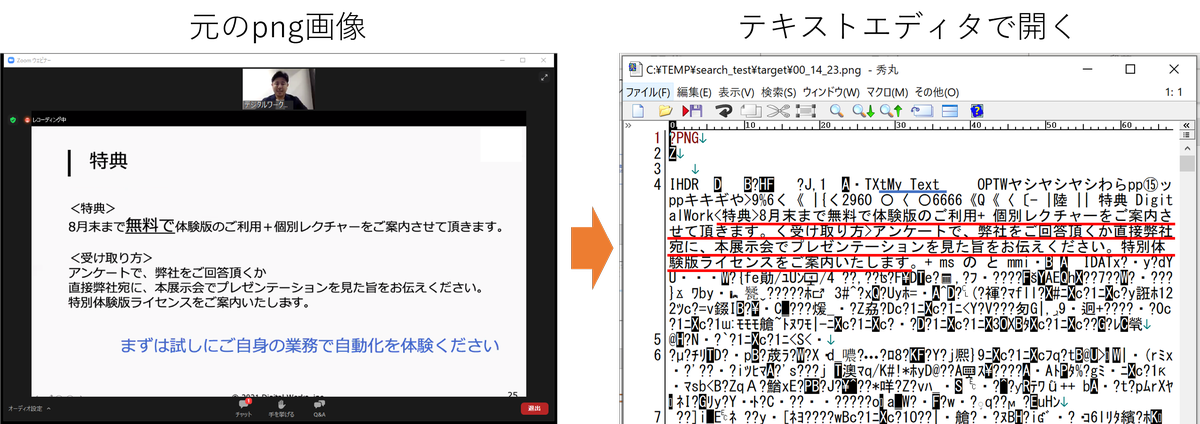
メタデータを埋め込んだ画像をテキストエディタで開く
上の画像のようにファイルの冒頭部分にそれらしいテキストが表示されているのがわかります。このように表示されていればOCRで文字起こししたテキストをpng 画像ファイルのメタデータとして首尾よく埋め込めたということです。
検索エンジンFESSをインストールする
Windowsの標準のデスクトップ検索(ローカルファイル検索)機能はpngなどの画像ファイルのメタデータ部分は検索対象としてくれません。このため別の検索エンジンをWindows内にインストールする必要があります。このエンジンがFESSということになります。
インストールの仕方については、以下の手順になります。
FESSインストールの手順
FESS自体は日本人エンジニアが開発してメンテナンスしているソフトなので、インストールの方法については、こちらの公式ページに日本語で非常に細かくきちんと記述されています。公式ページの説明に従って進めていけば完璧です。
FESSのインストールの途中、上記のFESSの公式ページの中に「環境変数」の設定という馴染みのない言葉が出てきます。個人的には「環境変数」などといわず「どこでもコマンド」などと言い換えた方が、理解されやすいと思っていますが、とにかく「環境変数」とやらに登録しておくと、いちいち特定の実行型ファイル、参照型ファイルがあるフォルダに移動しなくても実行したり参照したりすることができる、というだけのことです。まあ、ここは深く考えず書いてある通りにやってください。
FESSにスクショ画像をクロールさせ検索できる状態にする
FESSのインストール過程でzip ファイルをダウンロードして解凍します。解凍してできたフォルダfess-x.x.x (xの部分はダウンロードしたバージョン番号)のbinフォルダの中にあるfess.bat をダブルクリックすると黒い画面が表示されFESS が起動します。
FESS起動画面
この画面を閉じるとFESSも終了してしまうのでバツボタンで閉じないでください。
この状態で、ブラウザに、URLとして、http://localhost:8080/ と入れるとFESSの検索画面が表示されることになっています。ではブラウザを開いてURL欄に以下のように入れてみてください。
FESSのページを開く
何か表示されましたか? 何も表示されませんね。実はfess.bat をダブルクリックした後、1~2分待つ必要があるようです。エェィ、マニュアルにも書いてないし、こういうのすげー分かりにくい。
しばらく待ってからもう一度ブラウザにhttp://localhost:8080/ を入れると、ようやく出ました。FESSの検索画面です。この状態になればFESSのインストールは成功しています。
FESSのトップ画面
右上の「ログイン」をクリックするとID,PWを入力するページに遷移するので ID, PWともadmin と入力してログインしてください。初回ログイン後にパスワードを変えろと指示されたら適当に変えてください。今回の用途では、自分のPCの中で自分しか使わない検索エンジンという前提なのでID,PWは本当に適当でいいです。
FESSのインストールは成功したので、次は検索クローラーの設定です。http://localhost:8080/ から入った場合、以下の図のようにadmin →「管理」を開いてください。
FESSの管理画面を開く
左側の「クローラー」というメニューから「ファイルシステム」を選択して「新規作成」を押します。
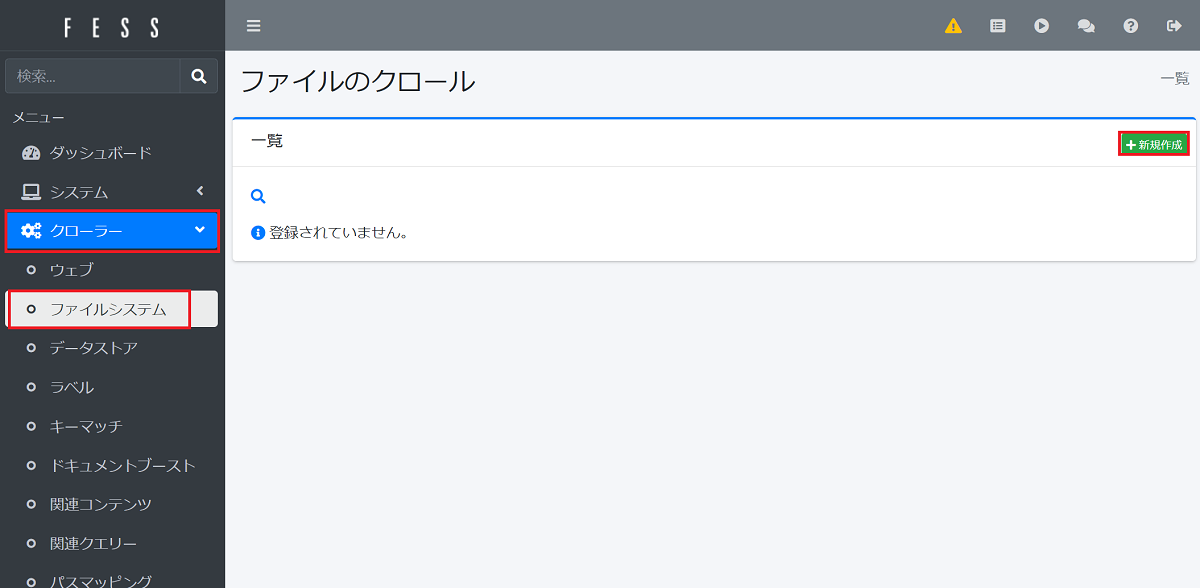
FESSのクローラーを設定する(1)
スクショ画像を保存しているフォルダがC:\TEMP\search_test\targetで、この中にさらに1階2層フォルダ構造がある場合は以下のように設定します。
| 項目 | 入力値 |
|---|---|
| 名前 | 画像検索 (←適当で良いです) |
| パス | file:/C:/TEMP/search_test/target/ |
| クロール対象とするパス | file:/C:/TEMP/search_test/target/.* |
| 深さ | 2 |
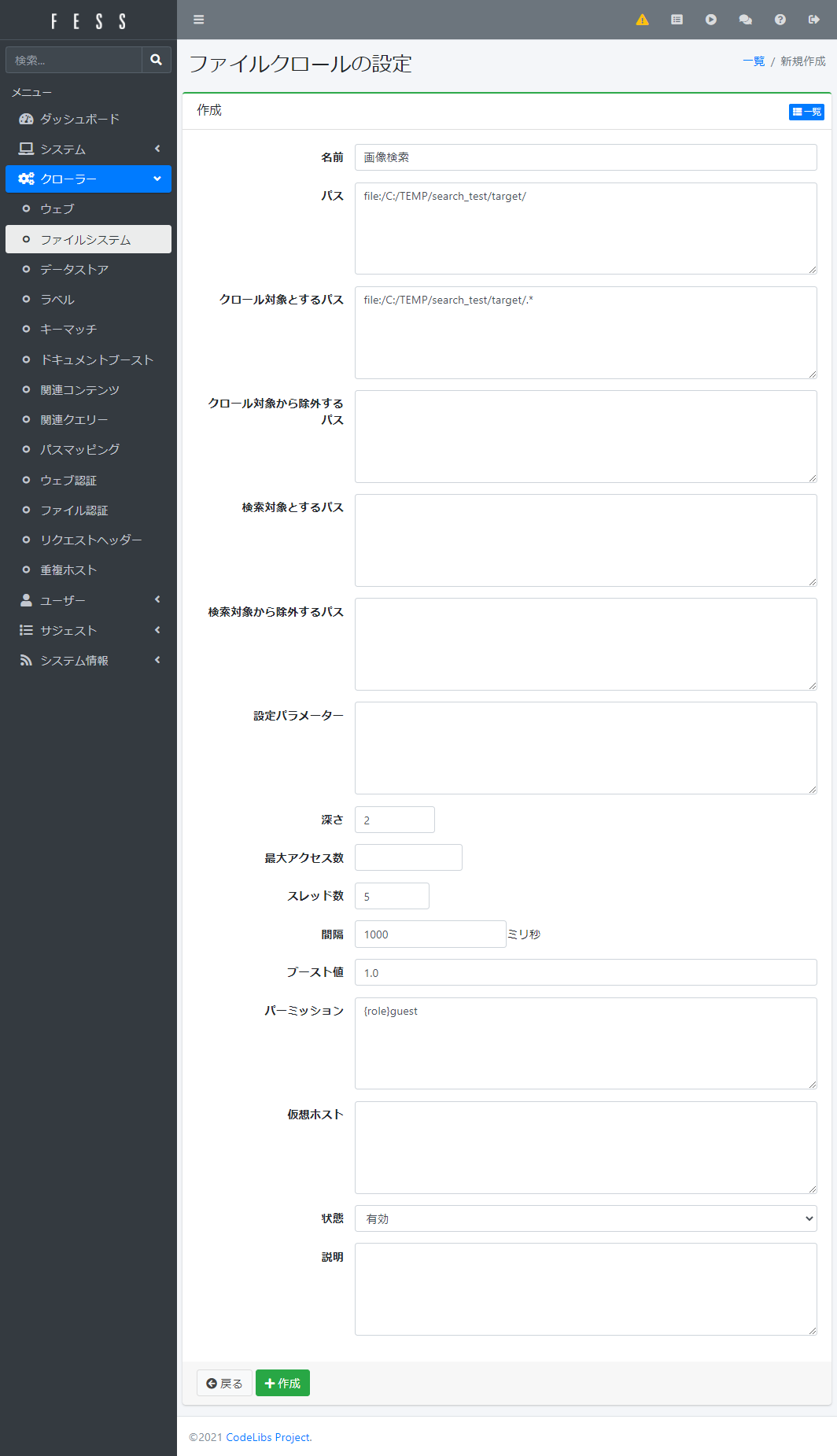
FESSのクローラーを設定する(2)
一番下の「+作成」というボタンを押して出来上がりです。
FESSのクロールをすぐ開始するためには、システム→スケジューラ→Default Crawlerをクリック →下の方のボタンで「今すぐ開始」を押します。
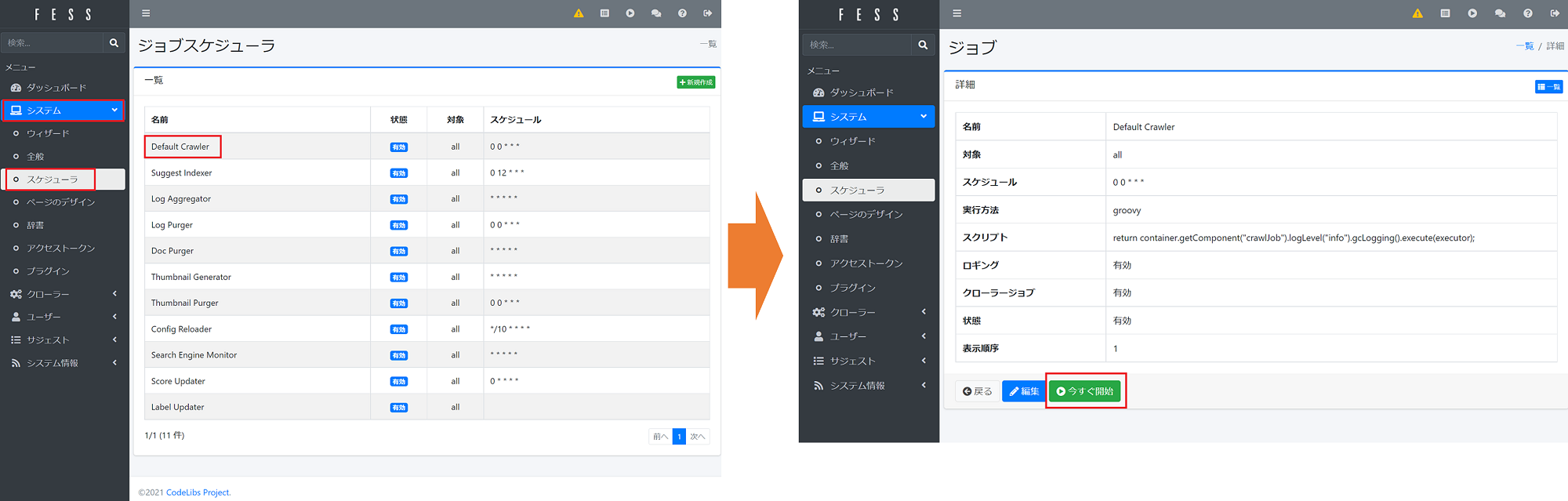
FESSのクローラーを設定する(3)
ジョブスケジューラに自動で戻りますが特に変化していないように見えます。しかしここでブラウザのリロードボタンを押すと、クロール処理が「実行中」となりますので、ああ、動いているんだ、と安心します。FESSは細かい部分の作りは少し不親切ですが、開発者の日本人はたった一人でFESSを開発・メンテされているようなので、無理もないです。
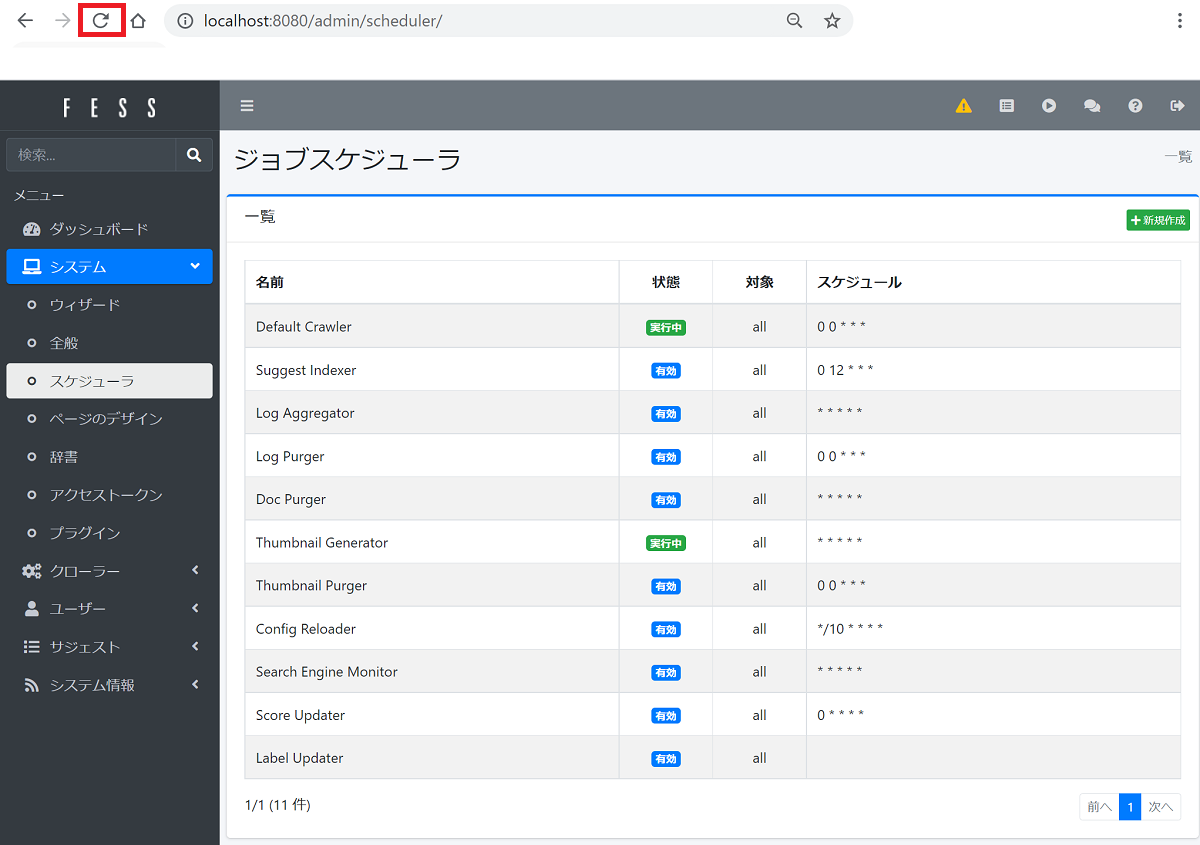
FESSのクローラーを設定する(4)
ある程度待ってからリロードボタンを押し「実行中」と表示されていた Default Crawler が「有効」に戻っていたらFESSのクロールは完了です。元の検索画面に戻ってキーワードを入れてみましょう。以下のように検索結果が表示されたら完璧です。
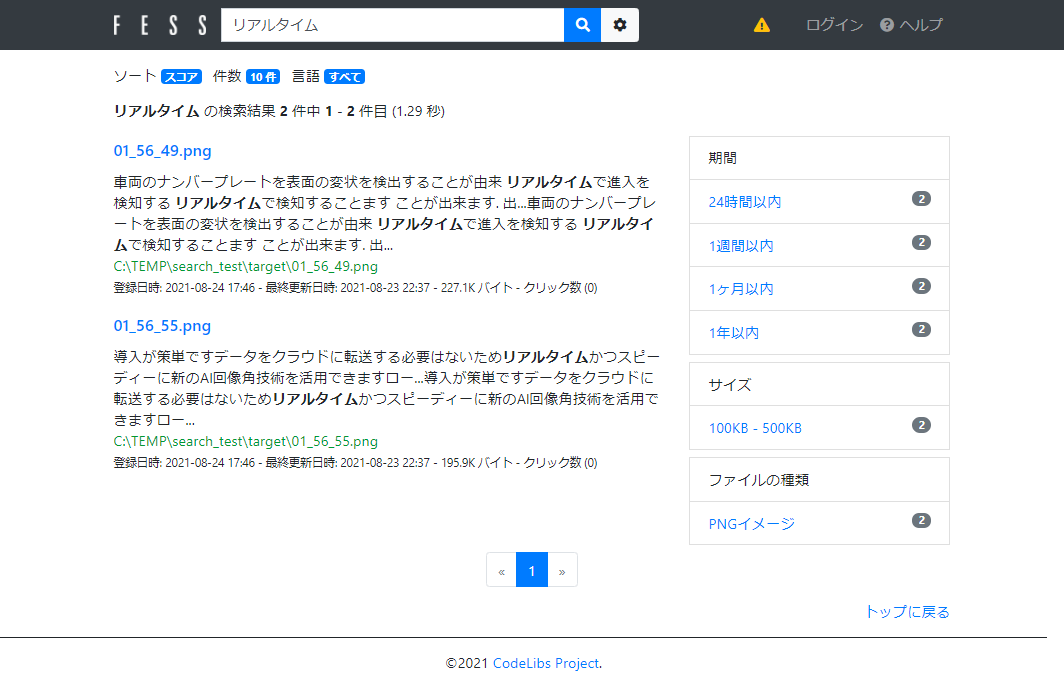
FESSの検索結果
これで凄まじい枚数の会議スクショ画像も検索対象になり、いつでも自分の知識の引き出しとして活用できるようになりました。自分の知的能力が一段高まりましたね。まさに人間の頭脳を支援するためのITという感じなので、私はこういうの好きです。
最後にまとめ
コロナの影響でオンライン会議・オンラインセミナーのスクショが膨大に溜まって来た人に朗報です。あなたがスクショしてきた大量のpng画像をOCRで文字起こししてpng 画像のメタデータ部分にテキストを埋め込んでしまいましょう。短いpythonのコードで簡単にOCRから埋め込み処理まで完了します。その後、高性能なローカル検索エンジンFESSをインストールすると、先ほどテキストを埋め込んだpng 画像のメタデータ部分まで検索対象としてクロールしてくれるので、画像上に書かれている文字をテキストで検索することができるようになります。ぱちぱち。

